Когда я только начинал изучать тему разработки сайтов, кракозябры были одной из моих постоянных проблем. Создал HTML-страницу — в браузере кракозябры, установил денвер и попробовал создать сайт на PHP — снова вместо букв кракозябры. Скачал иностранную тему, подключился к базе данных — та же проблема.
На своих сайтах я обычно использую UTF-8 (это такая кодировка текста, она ещё называется юникод), соответственно она будет присутствовать во всех примерах в этой статье.
1. UTF-8 без BOM
Начнём с самой простой проблемы. Вы создали какой-то HTML-файл, открыли его в браузере и получили:
Кракозябры (проблема с кодировкой).
Проблема актуальна в основном для пользователей Windows, на маке я с таким ни разу не сталкивался.
Решение проблемы зависит в основном от того, каким редактором вы пользуетесь. Для пользователей Windows я рекомендую бесплатный офигительный Notepad++.
Значит, открываем файл в Notepad++ и переходим в Кодировки > Преобразовать в UTF-8 без BOM. Вопрос — почему без BOM? Потому что с BOM у вас будут постоянно вставляться пустые символы (на самом деле они не пустые, у них тоже есть своя функция, но нам она в данном случае не нужна) куда не надо, а для PHP это уже критично.

2. Мета тег charset
Если вы сделали то, что я описывал в предыдущем шаге и ваша проблема не разрешилась, тогда самое время испробовать второй метод устранения кракозябров.
Всё, что нам требуется, это вставить следующий код между тегами
сайта. Прежде всего проверьте, возможно этот метатег у вас уже присутствует. Если да, то посмотрите какое у него стоит значение параметра charset.3. .htaccess
Если русские буквы до сих пор отображаются кракозябрами, тогда открываем ваш.htaccess , который лежит в корне сайта и вставляем туда с новой строки это:
Важно! Этот код должен вставляться до того, как будет что-либо выведено на странице сайта, иначе — ошибка.
5. Проблемы с последним символом при обрезке строки

Как решить эту проблему?
Легко — всё что нам нужно, это найти функцию substr() в коде и поменять её на mb_substr() .
Если после этого у вас полезут ошибки на сайт, то скорее всего multibyte-функции не поддерживаются вашим хостингом, первое, что вам следует сделать, это написать в супорт и спросить, нельзя ли их подключить на ваш аккаунт. Если нет, меняем хостинг, например на тот, которым .
6. MySQL
У меня не раз бывало такое, что я подключался к MySQL, вытаскивал какие-нибудь данные, и при их выводе на сайте, текст отображался кракозябрами.
В ремя от времени происходит так, что в операционной среде Windows вместо кириллических символов мы видим полную абракадабру: нагромождение иероглифов и непонятных значков, лишенных какого-либо смысла. Причин тому может быть несколько: начиная от неправильного выбора локали(параметров) в региональных настройках до некорректной инсталляции языкового русскоязычного пакета для поддержки кириллицы в англоязычной среде. Как бы то ни было, эта проблема вполне разрешима, и в этой статье мы расскажем, как ее преодолеть.
Наиболее вероятная причина возникновения проблемы, почему мы видим кракозябры вместо русских букв в Windows 10 – это неправильно выставленные установки локали (другими словами региональных настроек). В результате этого при попытке системы отобразить кириллические шрифты на экране мы видим полную сумятицу и хаос, при чем такое наблюдается не со всеми русскими символами. Насколько вы можете заметить из представленного ниже скриншота, некорректно отображаются не все символы. Так, наименования программ и ярлыков на рабочем столе написаны полностью корректно, а вот при попытке вызвать инсталлятор с описанием на русском наша проблема тут же вылазит на передний план, и мы видим кракозябры вместо русских букв.
Помимо некорректной установки локали, это может быть вызвано тем, что вы изначально установили англоязычную версию дистрибутива Windows, "заточенную” под латиницу. В этом случае все, что нам нужно сделать, — это на русскоязычную версию. Но мы будем подразумевать, что вы хотите работать именно с англоязычной средой, в которой все русские символы должны отображаться корректно и без ошибок, вне зависимости от того, какими программами вы пользуетесь, английскими или русскими. Как сделать так, чтобы не отображались кракозябры вместо русских букв в Windows 10 – читайте дальше.
Первое, что нам нужно сделать для преодоления сложившейся ситуации, — это зайти в панель управления. Осуществить данную операцию можно рядом методов, наиболее очевидный из которых – это применить правое нажатие кнопки мышки на пуске, после чего в возникшем меню выбрать соответствующее значение из списка.

В открывшемся окне панели управления выбираем раздел «Часы, язык и регион». Именно здесь сконцентрированы все региональные настройки: выбор часового пояса, разделители дробной и целой частей для чисел с плавающей точкой, обозначения валют, группировка крупных чисел по заданным признакам. Выбираем обозначенный выше раздел.

Войдя в описанную ранее категорию, отдаем предпочтение сектору «Региональные стандарты».

Помимо локали, здесь также можно задать настройки числа знаков после запятой, системы измерения (метрической или американской), формата чисел меньше нуля. Но нас прежде всего интересует региональная локаль для корректной репрезентативности кириллических символов в среде, чтобы не отображались кракозябры вместо русских букв в Windows 10. Чтобы задать ее параметры, перейдем на закладку «Дополнительно».

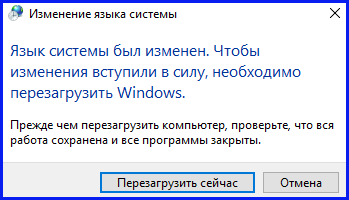
В категории, где устанавливается язык приложений, по дефолту не поддерживающих Юникод, щелкаем на кнопке «Изменить язык системы». В результате мы попадем на форму для кастомизации локали операционной среды, что нам, собственно, и нужно.

В возникшем на дисплее мини-окне выбираем «Русский (Россия)» в качестве текущего языка системы, тем самым указываем, что используемым по умолчанию в операционной среде языком будет именно русский, тем самым явно задавая соответствующий режим региональных настроек.

Далее в системе появится предупреждение о том, что в региональные параметры среды были внесены изменения, для вступления в силу которых понадобится перезагрузка системы. Соглашаемся с этим, перезагружаемся, и проверяем результате. В результате, кракозябры вместо русских букв в Windows 10 отображаться больше не должны, что можно проверить, еще раз запустив тот же самый, ранее проблемный дистрибутив на установку, либо любой другой, с отображением которого ранее возникали проблемы.
Как видим, возникшие трудности успешно разрешились, и теперь все шрифты должны отображаться корректно. Представленное вашему вниманию решение подходит в большинстве ситуаций, когда на экране отображаются кракозябры вместо русских букв в Windows 10.
Еще один способ решить описанную проблему – это выполнить определенные манипуляции с реестром. Но в силу возможной некорректной работы системы в результате их применения мы этот метод в нашем материале приводить не будем, так как в случае каких-либо ошибок с пользовательской стороны это может вылиться в необходимость полной переустановки операционной системы, а это для нас неприемлемо.
Итак, надеемся, что представленный выше алгоритм позволит вам обойти все подводные камни в решении вопроса, как убрать кракозябры в Windows 10 при работе в среде с англоязычной оболочкой, а также избавит вас от головной боли, связанной с отображением русскоязычных шрифтов в ОС.
Несколько раз мне доводилось сталкиваться с вопросами вроде: «я установил программу Х на мой компьютер, но при запуске все ее меню и названия кнопок в каких-то непонятных символах — абракадабра! »
Да, такое иногда встречается и среди пользователей подобные нечитаемые символ получили прозвище «кракозябры». Как правило, если эту же программу установить на другом компьютере, то все будет работать как надо и меню будет отображаться на русском языке.
Отчего же так происходит?
Дело в том, что в Windows есть так называемая кодовая страница, которая определяет, какие символы операционная система поддерживает. Есть несколько кодировок символов и не все разработчики программ используют кодировку Unicode (Юникод). Именно такие программы обычно и отображаются некорректно.
К тому же я почти уверен, что если вы столкнулись с подобной проблемой, то на вашем компьютере установлена не русскоязычная версия Windows , то есть сам интерфейс операционной системы на каком-то другом языке. Но то что язык интерфейса Windows не на русском еще не означает, что и интерфейс других программ должен быть на этом же языке. При установке Windows были выставлены некоторые параметры, которые нам нужно изменить и другие программы будут отображаться корректно.
Делается это просто — через . Заходим в Панель управления и находим раздел «Язык и региональные стандарты»:

Переходим на вкладку «Дополнительно» и обращаемся к блоку «Язык программ, не поддерживающих Юникод»:

В этом разделе должен быть установлен русский язык. Если это не так, нажимаем на кнопку «Изменить язык системы…», выбираем русский и после этого перегружаем компьютер.
Прошу не путать — кнопка «Изменить язык системы...» не поменяет язык интерфейса Windows. Она лишь позволит операционной системе правильно отображать программы, использующие другую кодировку символов!
После перезагрузки компьютера «абракадабра» вместе с «кракозябрами» исчезнут и все меню программы будут на русском языке.
Не упустите возможность сделать доброе дело.
Здравствуйте, уважаемые читатели, почитатели и прочие хорошие люди!
Случалось ли Вам получать и читать письма на “фиг каком пойми языке” или заходить на какой-нибудь интернет-ресурс и вместо привычных букв видеть сплошные кракозябры? Если да, тогда эта заметка для Вас, ибо в ней мы поговорим о кодировке страниц, её форматах, почему оная возникает и как впредь избежать непонятных иероглифов.
Итак, сегодня нас ждет не легкая софтовая статья, а суровая техническая, так что приготовьтесь: будем немного ударяться в суровые реалии.
Поехали.
Что такое кодировка текста и с чем ее едят?
Начать хотелось бы с того, что этой статьи могло бы и не быть, т.к. компьютерно-юзательная жизнь автора этих строк протекала вполне себе спокойно и достойно. Но вот в один прекрасный день, шляясь по просторам сети Интернет не со своего ПК, я столкнулся с непонятными явлениями на некоторых сайтах. Заходя на интернет-ресурсы, я видел не привычный нам русский алфавит и красивый понятный текст, а какую-то ересь в виде непонятной последовательности символов. Выглядела она примерно вот так (см. изображение).

Сначала я подумал, что моя любимая Мозилка (браузер Firefox) перегрелась и ей пора вызывать неотложку, но потом начал понимать, что проблема, скорее всего, на стороне ресурса сети и кроется она в неправильно настроенной кодировке. Это действительно оказалось так, и пошаманив немного с бубном, проблемка была оперативно решена. Результатом же всех моих любовных похождений и стал сегодняшний материал. Собственно, поехали разбираться в деталях.
Всю информацию, представленную в цифровом виде и находящуюся в глобальной паутине, нужно рассматривать с двух сторон: первая - со стороны пользователя (красивый и ухоженный текст на экране монитора) и вторая – со стороны поисковой машины (некий программный код, состоящий из различных тегов/метатегов, таблицы символов и прочее).
Если Вы хоть немного знакомы с языком разметки гипертекста (HTML ), то должны быть в курсе, что сайт глазами поисковых машин (Google, Яндекс ) видится не как обычный текст, а как структурированный документ, состоящий из последовательностей различного рода тегов. Чтобы было понятней, о чем я говорю, давайте взглянем на всеми нами любимый сайт Заметки Сис.Админа ” проекта [Sonikelf"s Project"s ], но не глазами обычного пользователя, а "глазами" поисковика. Для этого нажимаем сочетание клавиш Сtrl+U (для браузеров Firefox и Chrome ) и видим следующую картину (см. изображение):
![]()
Перед нами машинный вариант сайт , вот в таком вот непрезентабельном виде он подается поисковым системам и именно в таком виде они его и кушают. Если бы мы просто взяли и “засандалили” варианты статей из блокнота или Word обычным текстом, машины бы им не то что подавились, они бы даже и есть его не стали. Итак, перед нами главная страница проекта в HTML -виде. Обратите внимание на строку с надписью UTF-8 , это не что иное, как пресловутая кодировка текста страницы, именно она и отвечает за формат вывода информации в презентабельном виде, в результате чего через браузер мы видим нормальный текст.
Теперь давайте разберемся, почему же происходит так, что порой на экране монитора мы видим кракозябры. Все очень просто, проблема кроется в открытии файла в неверной кодировке. Если перевести на бытовой язык, то допустим Вас послали в магазин за молоком, а Вы притарабанили хлеб, вроде бы тоже съестное, но совсем другой формат продукта.
Итак, теперь давайте разбираться с теорией и для этого введем некоторые определения.
- Кодировка (или “Charset ”) – соответствие набора символов набору числовых значений. Нужна для “сливания” информации в интернет, т.е. текстовая информация преобразуется в биты данных;
- Кодовая страница (“Codepage ”) – 1 байтовая (8 бит) кодировка;
- Количество значений, принимаемое 1 байтом – 256 (два в восьмой).
Соответствие “символ-изображение” задается с помощью специальных кодовых таблиц, где каждому символу уже присвоен свой конкретный числовой код. Таких таблиц существует достаточно много, и в разных таблицах один и тот же символ может идентифицироваться по-разному (ему могут соответствовать разные числовые коды).
Все кодировки различаются количеством байт и набором специальных знаков, в которые преобразуется каждый символ исходного текста.
Примечание:
Декодирование – операция, в результате которой происходит преобразование кода символа в изображение. В результате этой операции информация выводится на экран монитора пользователя.
В общем.. С определениями разобрались, а теперь давайте узнаем, какие же (кодировки) бывают.
Виды кодировок текста
А их, в общем-то, хватает.
- ASCII
Одной из самых “древних” считается американская кодировочная таблица (ASCII , читается как “аски”), принятая национальным институтом стандартов. Для кодировки она использовала 7 битов, в первых 128 значениях размещался английский алфавит (в нижнем и верхнем регистрах), а также знаки, цифры и символы. Она больше подходила для англоязычных пользователей и не была универсальной.
- Кириллица
Отечественный вариант кодировки, для которого стали использовать вторую часть кодовой таблицы – символы с 129 по 256 . Заточена под русскоязычную аудиторию.
- Кодировки семейства MS Windows : Windows 1250-1258 .
8-битные кодировки, появились как следствие разработки самой популярной операционной системы, Windows . Номера с 1250 по 1258 указывают на язык, под который они заточены, например, 1250 – для языков центральной Европы; 1251 – кириллический алфавит.
- Код обмена информацией 8 бит – КОИ8
KOI8-R, KOI8-U, KOI-7 – стандарт для русской кириллицы в юникс-подобных операционных системах.
- Юникод (Unicode )
Универсальный стандарт кодирования символов, позволяющий описать знаки практически всех письменных языков. Обозначение “U+xxxx ” (хххх – 16-ричные цифры). Самые распространенные семейства кодировок UTF (Unicode Transformation Format) : UTF-8, 16, 32 .
В настоящее время, как говорится, “рулит” UTF-8 – именно она обеспечивают наилучшую совместимость со старыми ОС , которые использовали 8 -битные символы. В UTF-8 кодировке находятся большинство сайтов в сети Интернет и именно этот стандарт является универсальным (поддержка кириллицы и латиницы).
Разумеется, я привел не все виды кодировок, а только наиболее ходовые. Если же Вы хотите для общего развития знать их все, то полный список можно отыскать в самом браузере. Для этого достаточно пройти в нем на вкладку “Вид-Кодировка-Выбрать список ” и ознакомиться со всевозможными их вариантами (см. изображение).

Если Вы хотите знать больше, желаете научиться этому профессионально и понимать происходящее, то .
Думаю возник резонный вопрос: “Какого лешего столько кодировок? ”. Их изобилие и причины возникновения можно сравнить с таким явлением, как кроссбраузерность/кроссплатформенность. Это когда один и тот же сайт сайт отображается по-разному в различных интернет-обозревателях и на различных гаджет-устройствах. Кстати у сайта "Заметки Сис.Админа " с этим, как Вы заметили всё в порядке:).
Все эти кодировки – рабочие варианты, созданные разработчиками “под себя” и решение своих задач. Когда же их количество перевалило за все разумные пределы, а в поисковиках стали плодиться запросы типа: “Как убрать кракозябры в браузере? ” - разработчики стали ломать голову над приведением всей этой каши к единому стандарту, чтобы, так сказать, всем было хорошо. И кодировка Unicode , в общем-то, это “хорошо” и сделала. Теперь если такие проблемы и возникают, то они носят локальный характер, и не знают как их исправить только совсем непросвещенные пользователи (впрочем, часто беда с кодировкой и отображением сайтов появляется из-за того, что веб-мастер указал на стороне сервера некорректный формат, и приходится переключать кодировку в браузере).
Ну вот, собственно, пока вся "базово необходимая" теория, которая позволит Вам “не плавать” в кодировочных вопросах, теперь переходим к практической части статьи.
Решаем проблемы с кодировкой или как убрать кракозябры?
Итак, наша статья была бы неполной, если бы мы не затронули пользовательско-бытовые вопросы. Давайте их и рассмотрим и начнем с того, как (с помощью чего) можно посмотреть кодировку?
В любой операционной системе имеется таблица символов, ее не нужно докачивать, устанавливать – это данность свыше, которая располагается по адресу: “Пуск-программы-стандартные-служебные-таблица символов”. Это таблица векторных форм всех установленных в Вашей операционной системе шрифтов.

Выбрав “дополнительные параметры” (набор Unicode ) и соответствующий тип начертания шрифта, Вы увидите полный набор символов, в него входящих. Кликнув по любому символу, Вы увидите его код в формате UTF-16 , состоящий из 4 -х шестнадцатеричных цифр (см. изображение).

Теперь пара слов о том, как убрать кракозябры. Они могут возникать в двух случаях:
- Со стороны пользователя - при чтении информации в интернет (например, при заходе на сайт);
- Или, как говорилось чуть выше, со стороны веб-мастера (например, при создании/редактировании текстовых файлов с поддержкой синтаксиса языков программирования в программе ++ или из-за указания неправильной кодировки в коде сайта).
Рассмотрим оба варианта.
№1. Иероглифы со стороны пользователя.
Допустим, Вы запустили ОС и в каком-то из приложений у Вас отображаются пресловутые каракули. Чтобы это исправить, идем по адресу: “Пуск - Панель управления - Язык и региональные стандарты - Изменение языка
” и выбираем из списка, "Россия
".

Также проверьте во всех вкладках, чтобы локализация была “Россия/русский ” – это так называемая системная локаль.
Если Вы открыли сайт и вдруг поняли, что почитать информацию Вам не дают иероглифы, тогда стоит поменять кодировку средствами браузера (“Вид - Кодировка ”). На какую? Тут все зависит от вида этих кракозябр. Ориентируйтесь на следующую шпаргалку (см. изображение).

№2. Иероглифы со стороны веб-мастера.
Очень часто начинающие разработчики сайтов не придают большого значения кодировке создаваемого документа, в результате чего потом и сталкиваются с вышеозначенной проблемой. Вот несколько простых базовых советов для веб-мастеров, чтобы исправить беду.
Чтобы такого не происходило, заходим в редактор Notepad++ и выбираем в меню пункт “Кодировки ”. Именно он поможет преобразовать имеющийся документ. Спрашивается, какой? Чаще всего (если сайт на WordPress или Joomla ), то “Преобразовать в UTF-8 без BOM ” (см. изображение).
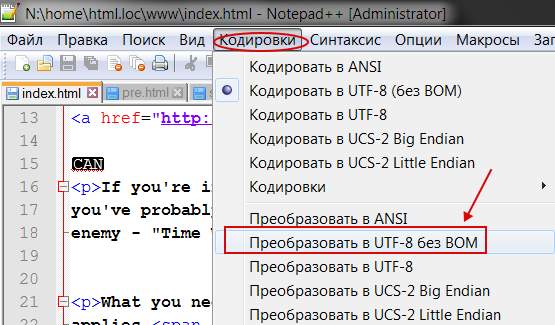
Сделав такое преобразование, Вы увидите изменения в строке статуса программы.
Также во избежание кракозябр необходимо принудительно прописать информацию о кодировке в шапке сайта. Тем самым Вы укажите браузеру на то, что сайт стоит считывать именно в прописанной кодировке. Начинающему веб-мастеру необходимо понимать, что чехарда с кодировкой чаще всего возникает из-за несоответствия настроек сервера настройкам сайта, т.е. на сервере в базе данных прописана одна кодировка, а сайт отдает страницы в браузер в совершенной другой.
Для этого необходимо прописать “внаглую” (в шапку сайта, т.е, как частенько, в файл header.php ) между тегами <head> </head> следующую строчку:
Прописав такую строчку, Вы заставите браузер правильно интерпретировать кодировку, и иероглифы пропадут.
Также может потребоваться корректировка вывода данных из БД (MySQL). Делается сие так:
mysql_query("SET NAMES utf8");
myqsl_query("SET CHARACTER SET utf8");
mysql_query("SET COLLATION_CONNECTION="utf8_general_ci"" ");
Как вариант, можно еще сделать ход конём и прописать в файл .htaccess такие вот строчки:
# BEGIN UTF8
AddDefaultCharset utf-8
AddCharset utf-8 *
CharsetSourceEnc utf-8
CharsetDefault utf-8
# END UTF8
Все вышеприведенные методы (или некоторые из них), скорее всего, помогут Вам и Вашим будущим посетителям избавиться от ненавистных иероглифов и проблем с кодировкой. К сожалению, более подробно мы здесь инструкцию по веб-мастерским штукам рассматривать не будем, думаю, что они обязательно разберутся в подробностях при желании (как-никак у нас несколько другая тематика сайта).
Ну, вот и практическая часть статьи закончена, осталось подвести небольшие итоги.
Послесловие
Сегодня мы познакомились с таким понятием, как кодировка текста. Уверен, теперь при возникновении каракулей на мониторе компьютера Вы не спасуете, а вспомните все приведенные здесь методы и решите вопрос в свою пользу!
На сим все, спасибо за внимание и до новых встреч.