В настоящее время большая часть пользователей при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др.
На основании одной ячейки информационной ёмкостью 1 бит можно закодировать только 2 различных состояния. Для того чтобы каждый символ, который можно ввести с клавиатуры в латинском регистре, получил свой уникальный двоичный код, требуется 7 бит. На основании последовательности из 7 бит, в соответствии с формулой Хартли, может быть получено N=2 7 =128 различных комбинаций из нулей и единиц, т.е. двоичных кодов. Поставив в соответствие каждому символу его двоичный код, мы получим кодировочную таблицу. Человек оперирует символами, компьютер – их двоичными кодами.
Для латинской раскладки клавиатуры такая кодировочная таблица одна на весь мир, поэтому текст, набранный с использованием латинской раскладки, будет адекватно отображен на любом компьютере. Эта таблица носит название ASCII (American Standard Code of Information Interchange) по-английски произносится [э́ски], по-русски произносится [а́ски]. Ниже приводится вся таблица ASCII, коды в которой указаны в десятичном виде. По ней можно определить, что когда вы вводите с клавиатуры, скажем, символ “*”, компьютер его воспринимает как код 42(10), в свою очередь 42(10)=101010(2) – это и есть двоичный код символа “*”. Коды с 0 по 31 в этой таблице не задействованы.
Таблица символов ASCII
| код | символ | код | символ | код | символ | код | символ | код | символ | код | символ |
| Пробел | . | @ | P | " | p | ||||||
| ! | A | Q | a | q | |||||||
| " | B | R | b | r | |||||||
| # | C | S | c | s | |||||||
| $ | D | T | d | t | |||||||
| % | E | U | e | u | |||||||
| & | F | V | f | v | |||||||
| " | G | W | g | w | |||||||
| ( | H | X | h | x | |||||||
| ) | I | Y | i | y | |||||||
| * | J | Z | j | z | |||||||
| + | : | K | [ | k | { | ||||||
| , | ; | L | \ | l | | | ||||||
| - | < | M | ] | m | } | ||||||
| . | > | N | ^ | n | ~ | ||||||
| / | ? | O | _ | o | DEL |
Для того чтобы закодировать один символ используют количество информации равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события):
К = 2 I = 2 8 = 256,
т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
Необходимо помнить, что в настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ - 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы, не будут правильно отображаться в другой кодировке. Наглядно это можно представить в виде фрагмента объединенной таблицы кодировки символов.
Одному и тому же двоичному коду ставится в соответствие различные символы.
| Двоичный код | Десятичный код | КОИ8 | СР1251 | СР866 | Мас | ISO |
| б | В | - | - | Т |
Впрочем, в большинстве случаев о перекодировке текстовых документов заботится на пользователь, а специальные программы - конверторы, которые встроены в приложения.
Начиная с 1997 г. последние версии Microsoft Office поддерживают новую кодировку. Она называется Unicode (Юникод) . Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=2 16 =65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 - #04FF)
Cyrillic Supplement (#0500 - #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита - в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
Чтобы определить числовой код символа можно или воспользоваться кодовой таблицей. Для этого в меню нужно выбрать пункт "Вставка" - "Символ", после чего на экране появляется диалоговая панель Символ. В диалоговом окне появляется таблица символов для выбранного шрифта. Символы в этой таблице располагаются построчно, последовательно слева направо, начиная с символа Пробел.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации и в настоящее время большая часть персональных компьютеров в мире (и наибольшее время) занято обработкой именно текстовой информации.
ASCII - базовая кодировка текста для латиницы
Традиционно для кодирования одного символа используется количество информации, равное 1 байту , то есть I = 1 байт = 8 битов.
Для кодирования одного символа требуется 1 байт информации. Если рассматривать символы как возможные события, то можно вычислить, какое количество различных символов можно закодировать: N = 2I = 28 = 256.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр. Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111.
Таким образом, человек различает символы по их начертаниям, а компьютер - по их кодам. При вводе в компьютер текстовой информации происходит ее двоичное кодирование, изображение символа преобразуется в его двоичный код.
Пользователь нажимает на клавиатуре клавишу с символом, и в компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код символа). Код символа хранится в оперативной памяти компьютера, где занимает один байт. В процессе вывода символа на экран компьютера производится обратный процесс - декодирование, то есть преобразование кода символа в его изображение. В качестве международного стандарта принята кодовая таблица ASCII (American Standart Code for Information Interchange) Таблица стандартной части ASCII Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода (с 0 по 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и так далее). Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания. Коды с 128 по 255 являются национальными, то есть в национальных кодировках одному и тому же коду соответствуют различные символы.
К сожалению, в настоящее время существуют пять различных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, поэтому с его помощью можно закодировать не 256 символов, а N = 216 = 65536 различных
Юникод - появление универсальной кодировки текста (UTF 32, UTF 16 и UTF 8)
Эти тысячи символов языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных кодировках ASCII. В результате был создан консорциум под названием Юникод (Unicode - Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой кодировкой текста, вышедшей под эгидой консорциума Юникод, была кодировка UTF 32 . Цифра в названии кодировки UTF 32 означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного символа в новой универсальной кодировке UTF 32.
В результате чего один и то же файл с текстом, закодированный в расширенной кодировке ASCII и в кодировке UTF 32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью UTF 32 число символов равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество символов использовать в кодировке вовсе и не было необходимости, однако при использовании UTF 32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много и такое расточительство себе никто не мог позволить.
В результате развития универсальной кодировки Юникод появилась UTF 16 , которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. UTF 16 использует два байта для кодирования одного символа. Например, в операционной системе Windows вы можете пройти по пути Пуск - Программы - Стандартные - Служебные - Таблица символов.
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберите в Дополнительных параметрах набор символов Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из этих символов вы сможете увидеть его двухбайтовый код в кодировке UTF 16, состоящий из четырех шестнадцатеричных цифр:
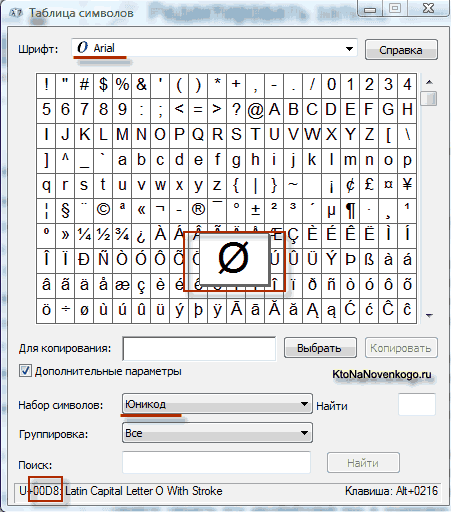
Сколько символов можно закодировать в UTF 16 с помощью 16 бит? 65 536 символов (два в степени шестнадцать) было принято за базовое пространство в Юникод. Помимо этого существуют способы закодировать с помощью UTF 16 около двух миллионов символов, но ограничились расширенным пространством в миллион символов текста.
Но даже удачная версия кодировки Юникод под названием UTF 16 не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии кодировки ASCII к UTF 16 вес документов увеличивался в два раза (один байт на один символ в ASCII и два байта на тот же самый символ в кодировке UTF 16). Вот именно для удовлетворения всех и вся в консорциуме Юникод было решено придумать кодировку текста переменной длины .
Такую кодировку в Юникод назвали UTF 8 . Несмотря на восьмерку в названии UTF 8 является полноценной кодировкой переменной длины, т.е. каждый символ текста может быть закодирован в последовательность длинной от одного до шести байт. На практике же в UTF 8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить.
В UTF 8 все латинские символы кодируются в один байт, так же как и в старой кодировке ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в UTF 8. Т.е. базовая часть кодировки ASCII перешла в UTF 8.
Кириллические же символы в UTF 8 кодируются в два байта, а, например, грузинские - в три байта. Консорциум Юникод после создания кодировок UTF 16 и UTF 8 решил основную проблему - теперь у нас в шрифтах существует единое кодовое пространство. Производителям шрифтов остается только исходя из своих сил и возможностей заполнять это кодовое пространство векторными формами символов текста.
Теоретически давно существует решение этих проблем. Оно называетсяUnicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодированоN=2 16 =65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 - #04FF)
Cyrillic Supplement (#0500 - #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита - в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5, 3, 1.
Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
Итак, в мы выяснили, что в большинстве современных кодировок под хранение на электронных носителях информации одного символа текста отводится 1 байт. Т.е. в байтах измеряется объем (V), занимаемый данными при их хранении и передаче (файлы, сообщения).
Объем данных (V) – количество байт, которое требуется для их хранения в памяти электронного носителя информации.
Память носителей в свою очередь имеет ограниченную ёмкость , т.е. способность вместить в себе определенный объем. Ёмкость памяти электронных носителей информации, естественно, также измеряется в байтах.
Однако байт – мелкая единица измерения объема данных, более крупными являются килобайт, мегабайт, гигабайт, терабайт…
Следует запомнить, что приставки “кило”, “мега”, “гига”… не являются в данном случае десятичными. Так “кило” в слове “килобайт” не означает “тысяча”, т.е. не означает “10 3 ”. Бит – двоичная единица, и по этой причине в информатике удобно пользоваться единицами измерения кратными числу “2”, а не числу “10”.
1 байт = 2 3 =8 бит, 1 килобайт = 2 10 = 1024 байта. В двоичном виде 1 килобайт = &10000000000 байт.
Т.е. “кило” здесь обозначает ближайшее к тысяче число, являющееся при этом степенью числа 2, т.е. являющееся “круглым” числом в двоичной системе счисления.
Таблица 10.
|
Именование |
Обозначение |
Значение в байтах |
|
|
килобайт | |||
|
мегабайт |
2 10 Kb = 2 20 b | ||
|
гигабайт |
2 10 Mb = 2 30 b | ||
|
терабайт |
2 10 Gb = 2 40 b |
1 099 511 627 776 b |
|
В связи, с тем, что единицы измерения объема и ёмкости носителей информации кратны 2 и не кратны 10, большинство задач по этой теме проще решается тогда, когда фигурирующие в них значения представляются степенями числа 2. Рассмотрим пример подобной задачи и ее решение:
В текстовом файле хранится текст объемом в 400 страниц. Каждая страница содержит 3200 символов. Если используется кодировка KOI-8 (8 бит на один символ), то размер файла составит:
Решение
Определяем общее количество символов в текстовом файле. При этом мы представляем числа, кратные степени числа 2 в виде степени числа 2, т.е. вместо 4, записываем 2 2 и т.п. Для определения степени можно использовать Таблицу 7.
символов.
2) По условию задачи 1 символ занимает 8 бит, т.е. 1 байт => файл занимает 2 7 *10000 байт.
3) 1 килобайт = 2 10 байт => объем файла в килобайтах равен:
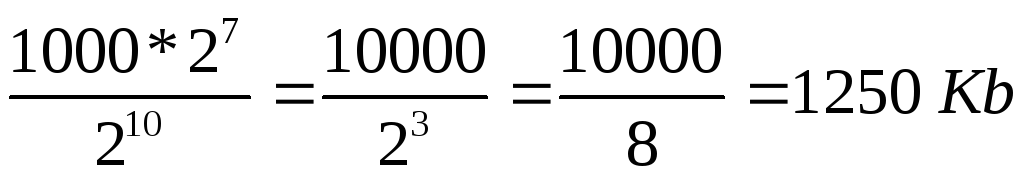 .
.
Сколько бит в одном килобайте?
&10000000000000.
Чему равен 1 Мбайт?
1000000 байт.
1024 байта;
1024 килобайта;
Сколько бит в сообщении объемом четверть килобайта? Варианты: 250, 512, 2000, 2048.
Объем текстового файла 640 Kb . Файл содержит книгу, которая набрана в среднем по32 строки на странице и по64 символа в строке. Сколько страниц в книге: 160, 320, 540, 640, 1280?
Досье на сотрудников занимают 8 Mb . Каждое из них содержит16 страниц (32 строки по64 символа в строке). Сколько сотрудников в организации: 256; 512; 1024; 2048?
Unicode (Юникод) - это стандарт кодирования символов, где каждому символу присваивается свой уникальный код, независимо от программной и аппаратной платформы.
Изначально для кодирования символов использовали 8 бит, которые дают 256 комбинаций нулей и единиц. Этого вполне достаточно чтобы закодировать весь латинский алфавит, цифры, знаки препинания, арифметические знаки, специальные управляющие символы. Стандартом стал ASCII. К тому же удобно и компактно, когда один символ равен одному байту.
Но 256 значений не достаточно, для того чтобы поместить туда еще символы других языков. Таких как греческий алфавит, кириллица, китайские иероглифы, математические символы и т.д. Что неудивительно, ведь ASCII - американский стандартный код, разрабатывался американцами, для американцев.
Уже вначале 70-х компьютеры распространились от университетов, вычислительных центров, закрытых государственных учреждений до небольших частных предприятий и домашних пользователей. США, Канада. Великобритания перестают быть монополистами в мире информационных технологий. В каждой стране есть свои вычислительные центры, IT-университеты и патенты в этой отрасли.
Как следствие, появляется огромное количество альтернативных кодировок. Ведь каждой письменности, нужны свои места в кодовой таблицы. Но вместе с тем появляется масса проблем.
Первая из них - это неправильное отображение документов одной кодировки в другой. Для того чтобы документ приобрел читабельный вид, необходимо иметь специальную таблицу, по которой машина сопоставит символы одной кодировки с другой. Для каждой пары кодировок нужна такая таблица. Альтернатива этому, использовать третью кодировку которая содержит все символы первых двух. Неудобно человеку и лишнее использование ресурсов машины.
Вторая проблема - шрифт, создается под определенную кодовую таблицу символов. Некоторые таблицы символов могут совпадать, более чем на 90%. Становиться не выгодно хранить разные шрифты, для (почти) одинаковых кодировок. Можно создавать универсальные шрифты. Но тогда потребуется хранить дополнительные данные, которые помогут разобраться, какие символы шрифта, каким символам кодировки соответствуют.
В начале 80-х кризис «крокозябры», в текстах, достиг своего пика. Необходимость в универсальной кодовой таблице стала очевидной. Нужен единый стандарт. Где поместились бы все символы. И в 1991 году такой стандарт был принят, консорциумомЮникод. Под названием Unicode. В консорциум вошли ведущие IT-предприятия, которые и определили, какой должна быть единая кодировка.
Если использовать кодировку с переменной шириной, то изначально потребуется дополнительные алгоритмы. Которые определят сколько нужно байт для хранения того или иного символа. Необходимо иметь алгоритмы которые, в цепочке бит, будут вычислять где конец, текущего символа, и где начало следующего. Решили, что все это будет сложно, и ввели кодировку с фиксированной шириной. Кодировка с переменной шириной, позволяет использует столько бит, сколько необходимо для хранении символ. Она намного компактнее. Этим фактором, изначально пренебрегли.
Сколько нужно бит, для нового стандарта Unicode? 8 бит даст 256 значений для символов (2 8 = 256). Практика доказала, это мало. 32 бита даст (2 32 = 2 294 967 296) позиций для символов. Это много. Слишком, не эффективное использование машинной памяти. Оптимальным вариантом, это взять 16 бит (2 16 = 65536). Таким образом первая версия Unicode была фиксированной шириной 16 бит. В нее вошли не все символы, а только самые употребляемые, содержавшиеся ране в известных кодировках. Например, в Unicode не попали, редко используемые китайские иероглифы. И не которые символы из высшей математики.
Каждый символ Unicode имеет свой порядковый номер. Который по стандарту записывается шестднадцатеричным числом.
Последние версии Unicode были сильно изменены. И первое, что решили, это хранить все существующие символы в данной кодировке. Символы в Unicode стали переменной длинны. Кодовую таблицу разбили на два пространства. В первом, хранят все наиболее употребляемые символы. Это в диапазоне от 0 до 65535. Остальное пространство используется для редко употребляемых символов. Любой символ можно представить несколькими кодами. Поэтому существующую таблицу Unicode постоянно нормализируют и выпускают новые версии. Современный Unicode поддерживает письменность слева направо так и на оборот справа налево, арабские символы. Он даже позволяет создавать двунаправленные тексты. Т.е в тексте, относящейся к одной кодовой таблице, могут содержаться символы, пишущиеся как справа налево так и наоборот. Но эту возможность должны поддерживать и аппаратные устройства.
В Unicode включает в себя не только символы различных языков. Но и узкоспециализируемые математические символы, ноты. В нем содержится все современные письменности. И даже редко используемые такие как коптское письмо, чероки, эфиопское. Для академических, кругов в кодовую таблицу, добавили даже вымершие письменности. Например: клинопись, руны, египетские иероглифы, этрусский алфавит.